Batch jobs
Batch jobs are background processes that run on a schedule to keep the system healthy, deliver notifications and emails, and keep projections in sync. A second category of jobs is reserved for troubleshooting — they don’t run on their own, but can be triggered manually to rebuild data or recover from problems.
Overview
Jobs are idempotent — running them multiple times on the same day is safe and produces consistent results. Each job records every execution (a “job run”) so you can inspect what happened, retry on a different date, or replay a single run.
Scheduled jobs
These jobs run automatically every day. The scheduler decides which workspace needs each job — workspaces with nothing to do are skipped. You can still trigger any of them manually if you want to force a run or experiment with a different run date.
Troubleshooting jobs
These jobs are operator-driven. They do not run on their own. Use them to rebuild a derived data set, recover from a failed migration, or refresh search indexes after configuration changes.
Viewing job history
Navigate to to see the history of all batch job executions.

The list shows:
- Started at — when the job began executing
- Job — the type of job that was run
- Status — current state (pending, started, completed, stopped, warning, or failed)
- Duration — how long the job took to complete
- Errors — number of errors encountered (if any)
Click on any row to view detailed results for that job run, including the parameters that were used and the counters returned by the job.

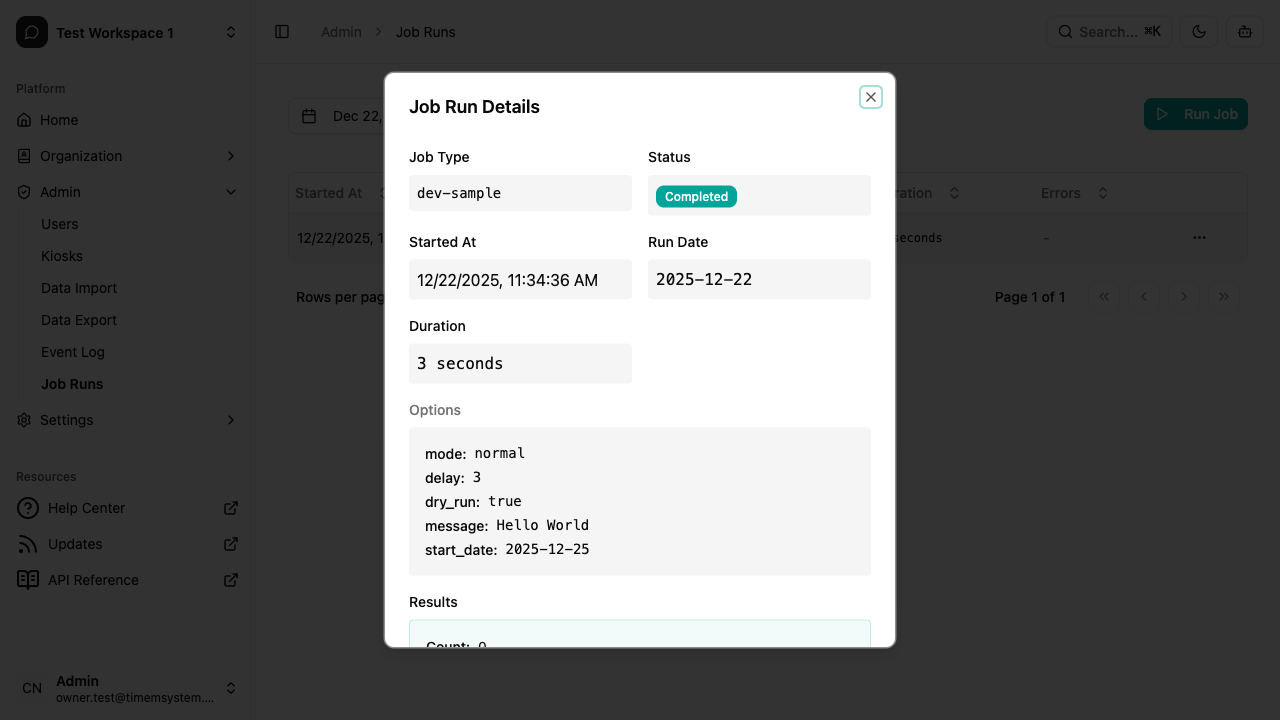
Status meanings
| Status | Meaning |
|---|---|
| pending | Queued, waiting for a worker to pick it up |
| started | Currently in progress |
| completed | Finished successfully |
| warning | Finished, but some entities were skipped or had per-row errors. The job did its job; the warnings are surfaced in the result counters |
| failed | Encountered a fatal error and stopped |
| stopped | Manually terminated before completion |
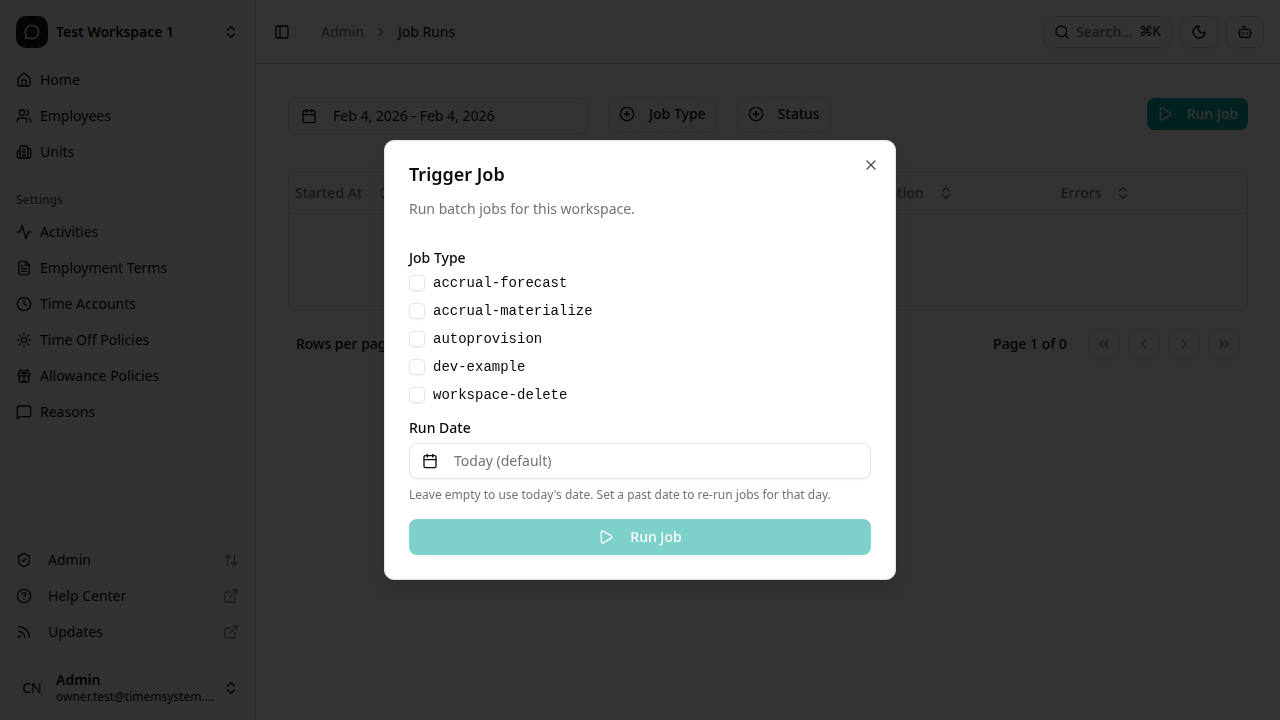
Running a job manually
You can trigger any job manually at any time:
- Click Run job
- Select one or more job types
- (Optional) Pick a run date other than today
- (Optional) Fill in the parameters specific to the selected job
- Click Run to start the job

When to use the run date
Most jobs interpret the run date as “the day this run is for”. The default is today. Picking another date is useful when you want to:
- Test what a job would do on a future day (e.g. an upcoming statement-period start)
- Catch up on a day the worker missed
- Re-run a job for a specific historical date

Parameters
When you select a job that accepts parameters, the dialog renders a form derived from the job’s declared options. Each job page below documents its specific parameters.
Common parameter types:
- Dry Run — fetch and report stats without making any changes. Available on jobs that delete or sync data
- Force / Force Recompute — bypass the “already done” checks and re-emit every item in scope
- Employee ID / Org Unit ID — narrow the scope of a rebuild to a single employee or one branch of the org tree